Create Hierarchies From Attributes
Hierarchies are great for analysis. You do not need to add another dimension to your cubes. If you are analysing your products by product type and you want to analyse where your products are manufactured. You can create a new hierarchy and add the elements that you need into the roll-ups that you want to see. This can be time-consuming. You might have hundreds of products, and you get the latest information from your ERP system and just bring the data in via a TI script.
In Planning Analytics v11 there is a button in the edit dimension option in the Data Modeler that will automatically generate a simple 3-level hierarchy for a specific attribute.
Click on the attribute and the Create Hierarchy option is shown:
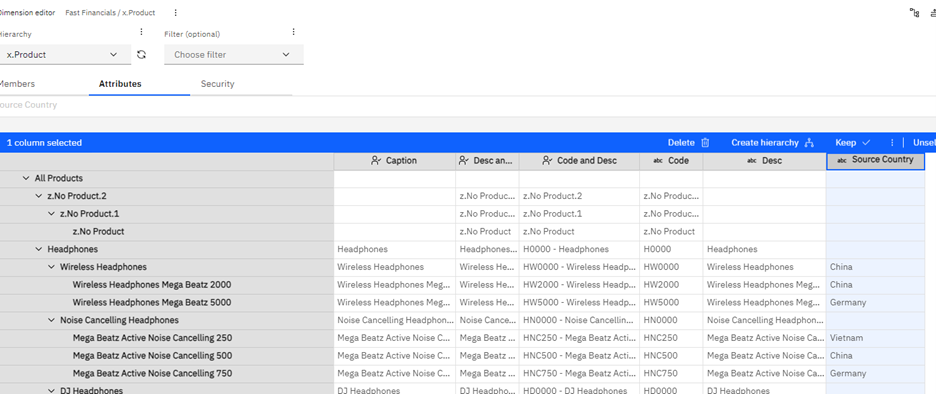
This functionality does not exist in Planning Analytics as an Engine and IBM does not plan to introduce it either. The handy shortcut in version 11 was seen as a bit gimmicky.
The good news is that you can replicate the effect very simply. I will show you how to below. You can cut and paste this into a new process.
Create a process that has no data source. We are just going to have three parameters. The dimension name, the attribute that you are going to use as the source of your new hierarchy and the name of the new hierarchy.
All the action takes place in the prolog section.
# Check if the dimension exists, if it returns 0 it does not, then quit the process
if (DimensionExists( pDimension )= 0);
ProcessQuit;
endif;
# Set the name of the cube that stores the attributes for the dimension. We use this to get the
# attribute value in the processing later.
vAttributeCubeName = ‘}ElementAttributes_’ | pDimension ;
# Does the hierarchy exist in the dimension?
# If it does not create it. If it does clear out all the elements of the hierarchy.
if (HierarchyExists( pDimension, pHierarchy )= 0);
HierarchyCreate( pDimension, pHierarchy );
else;
HierarchyDeleteAllElements( pDimension, pHierarchy );
endif;
# Now set up how the hierarchy is to be sorted
HierarchySortOrder( pDimension, pHierarchy, ‘By Name’, ‘Ascending’, ‘By Name’, ‘Ascending’ );
# Create the top level of the hierarchy e.g. ‘All Sources’
HierarchyElementInsertDirect( pDimension, pHierarchy, ”, ‘All ‘ | pHierarchy,’C’ );
# Calculate the number of elements in the dimension so that we can loop through the dimension members and select the ones that we want.
vDimensionElementCount = DIMSIZ( pDimension );
vCount = 1 ;
# Loop through the dimension
while (vCount <= vDimensionElementCount);
vElementName = DIMNM( pDimension, vCount );
vAttributeValue = ‘No Value’ ;
# Is this a leaf-level element? We only want the lowest level. If you take a consolidated
# element Planning Analytics will not allow this to be a consolidated element in a new hierarchy.
if (ElementLevel( pDimension, pDimension, vElementName )= 0);
# Does this have a value in the attribute that we are creating the hierarchy for
# You could use the ATTRS(dimension, element , attribute); consturct
if (CellGetS( vAttributeCubeName , vElementName, pAttribute) @<> ”);
vAttributeValue = CellGetS( vAttributeCubeName, vElementName , pAttribute );
# Does this attribute value already exist as a second-level element in the new hierarchy?
# If it does not exist, create the element in the hierarchy & assign it to the ‘All’ consolidation
if (HierarchyElementExists ( pDimension, pHierarchy, vAttributeValue ) = 0);
HierarchyElementInsertDirect ( pDimension, pHierarchy, ”, vAttributeValue, ‘C’ );
HierarchyElementComponentAddDirect( pDimension, pHierarchy, ‘All ‘ | pHierarchy, vAttributeValue, 1.000000 );
endif;
# Now add the leaf element. Add it to the attribute value’s consolidation e.g., Germany!
HierarchyElementComponentAddDirect( pDimension, pHierarchy, vAttributeValue, vElementName, 1.000000 );
endif;
# End of leaf-level condition
endif;
# Increment the count
vCount = vCount + 1 ;
end;
When we run our new process, we will get prompted:
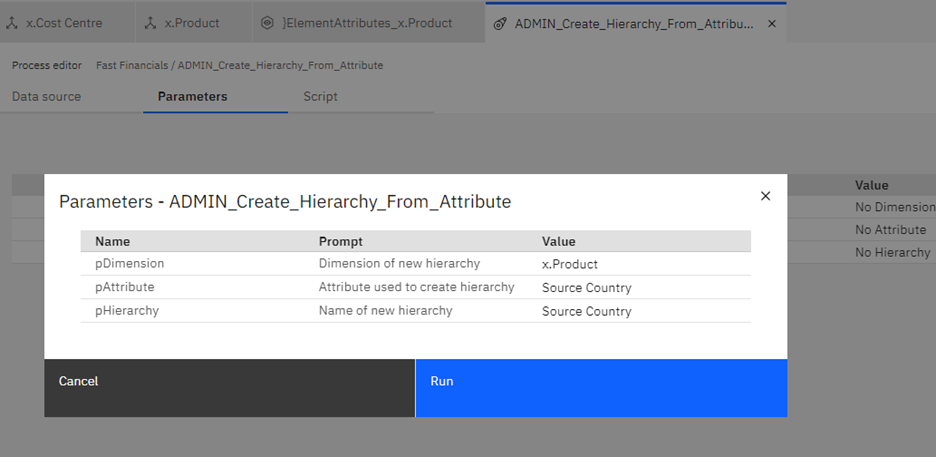
This will create a new hierarchy ‘Source Country’ where the values are taken from the ‘Source County’ text attribute:
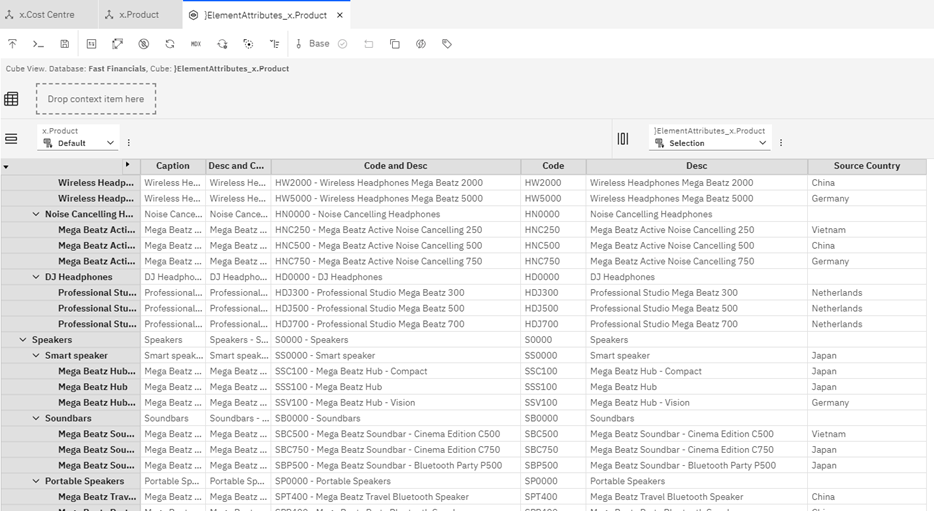
The hierarchy looks like this:
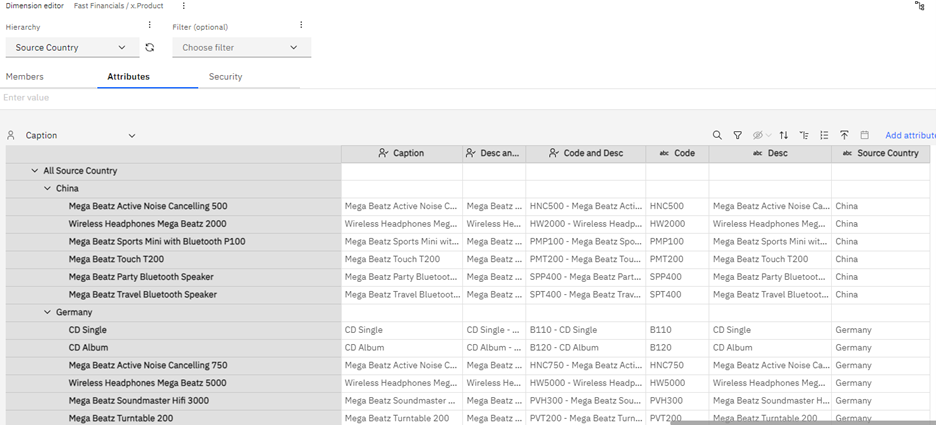
This means that we can now do analysis for products by product type e.g., Headphones, Speakers etc. and for each product type where they are sourced from e.g., China, Germany etc. We can see that the Netherlands sources over 20% of the revenue and Germany 30%.
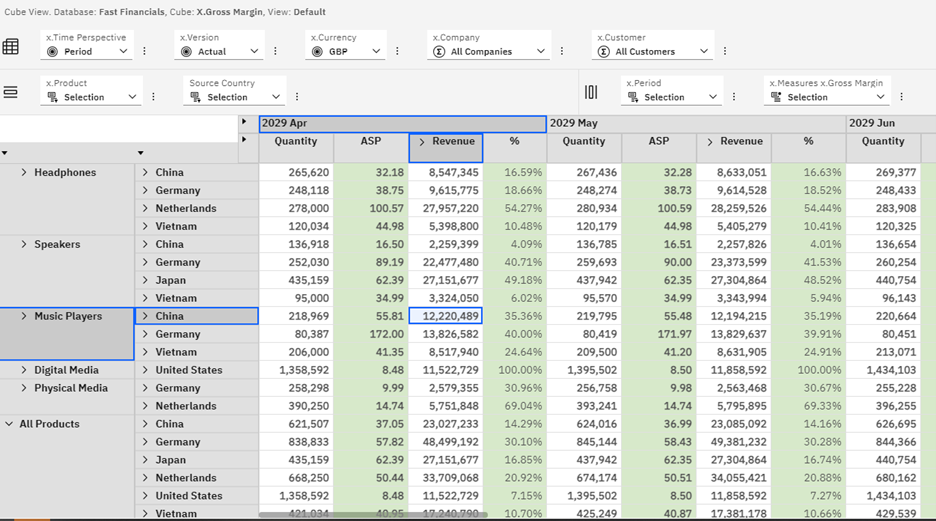
This process ignores those leaf elements which we do not categorize. This is fine for most of the analysis that I need to do. However, you can set up a bucket roll-up for those with a blank category e.g. ‘Others.’
After your analysis you may want to get rid of the hierarchy and delete the ‘Source Country’ attribute. You are not stuck with it.
Let us know your thoughts here.