In IBM Planning Analytics, Feeders solve a real modelling problem that we have in business reporting and planning systems. #
IBM Planning Analytics is very efficient at calculating totals. It does not calculate every single cell. It only calculates cells that have values. This is important in a business solution because the number of cells rapidly increase. A simple cube of 4 dimensions with 2 years of 12 periods, a customer list of 100, a product list of 12, 4 geographical regions and 3 measures of price, quantity and revenue would have (2*12) * 100 * 12 * 4 * 3 data points or 172,800. This means there are lots of cells without any data in them.
Feeders are the way that IBM Planning Analytics squares the circle of sparsity and speed.
How IBM Planning Analytics Calculates Totals #
To get a value IBM Planning Analytics operates a ‘pull’ method. A total is only calculated when it is needed. It is not stored, awaiting use.
In the example below, IBM Planning Analytics calculates the ‘Level 2’ value of 125 by adding the 3 ‘Level 0’ values (5,10 and 100) when the user wants the value. It ignores the 4 cells with no value. Even in this simple example, over 60% of cells are ignored.
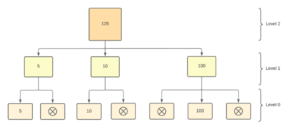
This works when the values have been added to the cells.
There’s more to life than totals #
IBM Planning Analytics would be limited if it just let us add things up quickly. Business systems are all about relationships and conditions. When x, do Y. IBM Planning Analytics lets you add formulas to a cell. IBM Planning Analytics calls these formulas, rules.
Let’s assume that the ‘Level 0’ figure is the measure ‘Revenue’ which can be calculated by the formula or rule ‘Price’ * ‘Quantity’.
[‘Revenue’] = N: [‘Price] * [‘Quantity’];
IBM Planning Analytics does not store this calculated value of Revenue. This immense benefit is counteracted by the fact that IBM Planning Analytics now needs to check each ‘Revenue’ cell to see if there should be a calculated value there, and, as we have seen, there can be a lot of cells, most of which will have no values.
We want our sparseness back #
To get our speed back we must tell IBM Planning Analytics not to check all the ‘Revenue’ cells on the off chance that there is something there. We do this with the command ‘SKIPCHECK’.
That’s all well and good, but now IBM Planning Analytics will just see empty cells. It will be fast but will not have any values! This is where we must take responsibility and tell IBM Planning Analytics that there should be a value in this specific cell. This is where feeders come in. A feeder sets a flag which tells the database to evaluate the rule to get the value.
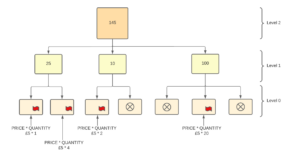
To set this flag you would go to the section in the cube rules file after all the rules have been declared. This area is started with the command FEEDERS;
We add the feeder command:
‘Quantity’ => ‘Revenue’;
Adding a ‘Quantity’ value will trigger the flag in the ‘Revenue’ cell. This will tell PA that there is a value in the ‘Revenue’ cell, and it will calculate it from this point. No value has been written, only a single byte set. This now gives a value of 145.
We now have our business complexity, and we have our speed.



